
Written by Naoki Yasuda (Kavli IPMU)
The galaxies PFS will observe are more than 8 billion light years away and their brightness is less than one to a 10 million of the stars visible to naked eyes. To measure the properties of these faint galaxies accurately, we have to develop data analysis software which can deal with various kinds of noises included in the acquired data.
From 20th to 22nd September 2017, researchers who will develop 2D data reduction pipeline have gathered at Princeton University, New Jersey, USA. Researchers coming from Princeton University, National Astronomical Observatory of Japan, and Kavli IPMU have discussed the
items to develop and roles of each person. Here “2D” data reduction means the processing to extract 1 dimensional spectra from the 2 dimensional images of detectors which record the output of 2394 fibers. After it, “1D” data reduction will follow to measure redshifts of galaxies and intensity of emission/absorption lines etc..
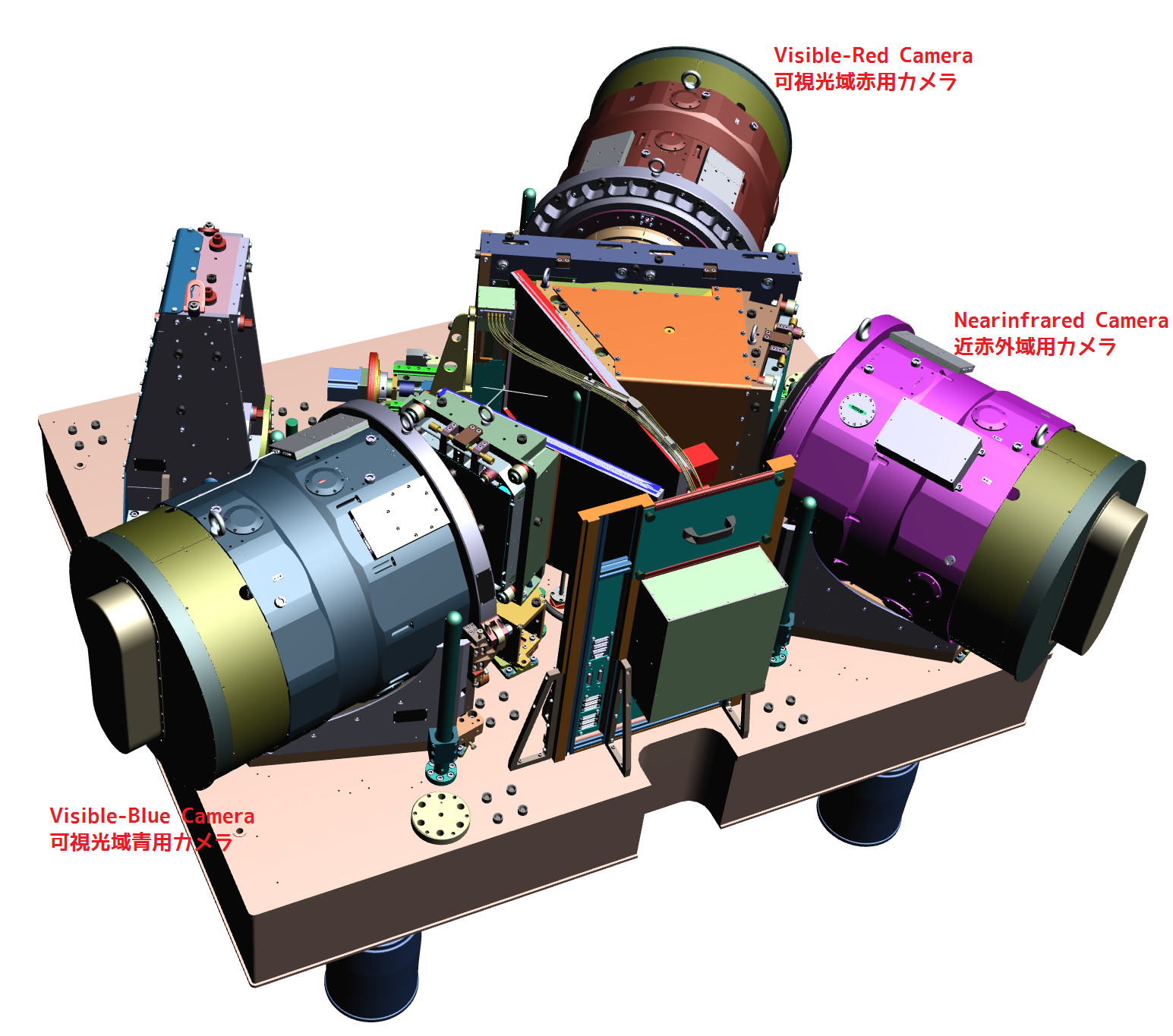
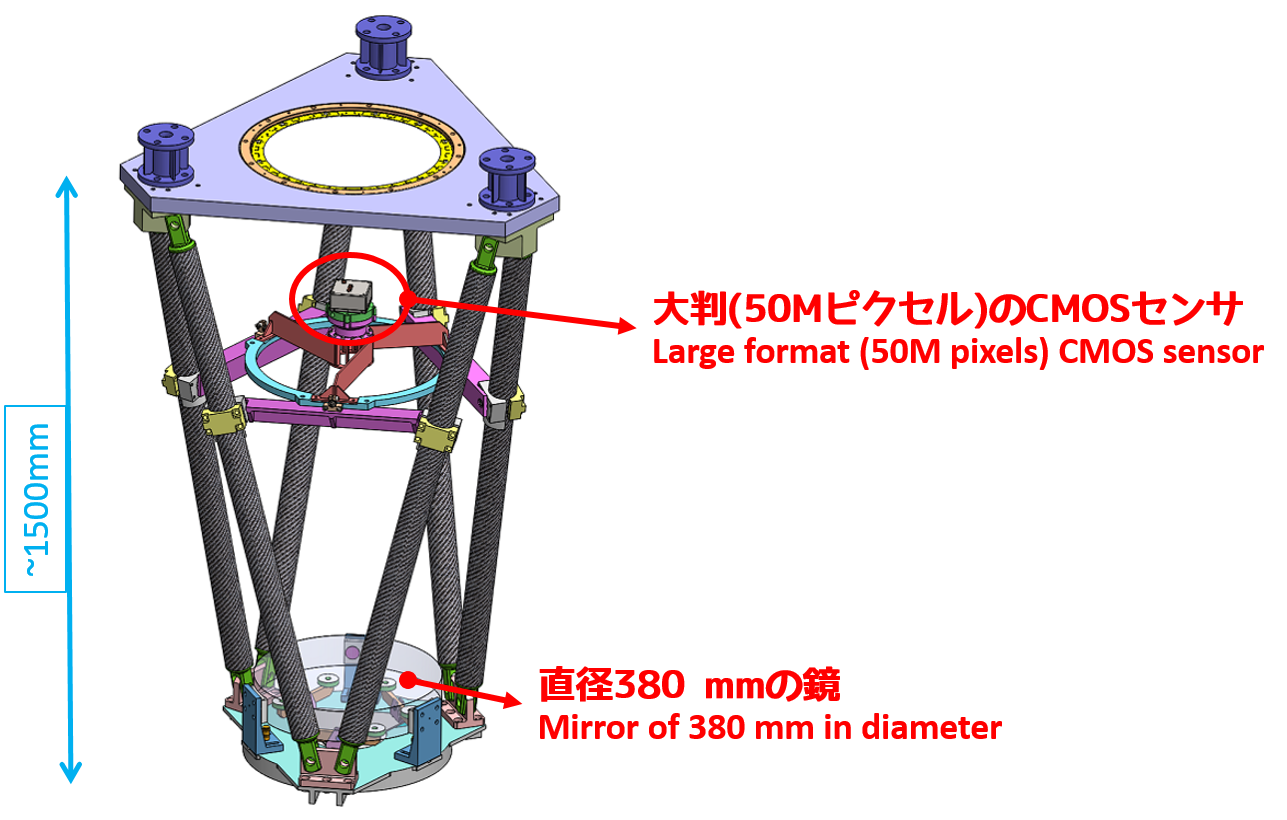
Within PFS, the light from each object will be directed to spectrograph through different fibers and the spectra will be recorded side by side on the detectors. The separation of the adjacent spectra is a bit small to maximize the number of objects to be observed and the spectra will overlap with each other. These spectra should be optimally separated. The characteristics of the fibers are slightly different and these effect also should be taken into account. Needless to say, both wavelength and flux should be calibrated precisely.

(Spectra taken at the laboratory. Since one 2D image has about 600 spectra, their separation is a bit small.)
In addition to these, the sky is 1000 times brighter than the objects we are planning to observe, even at the summit of Mt. Mauna Kea where Subaru telescope is placed (~4200 m high). This is caused by the OH air-glow. The emission lines by OH molecule is though to be observed at the specific wavelengths, so we have to remove the sky OH emission lines cleanly from the observed spectra.
In the meeting, we have listed up and confirmed these challenges we will face and decided to start development using simulated images assuming the observational conditions. We will prepare for the real observing data which will be delivered in 2019 at the engineering run.
{kind=link}