
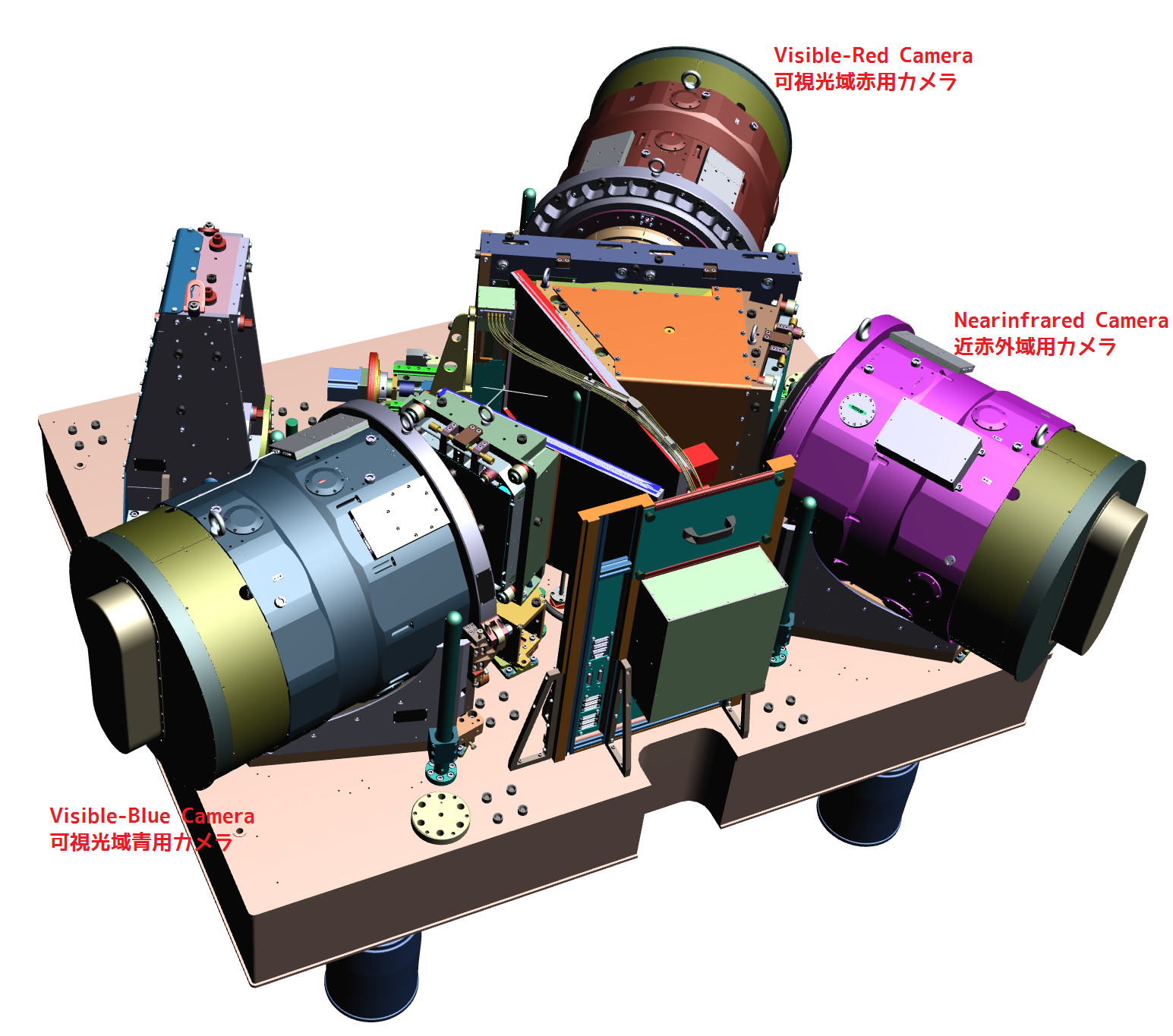
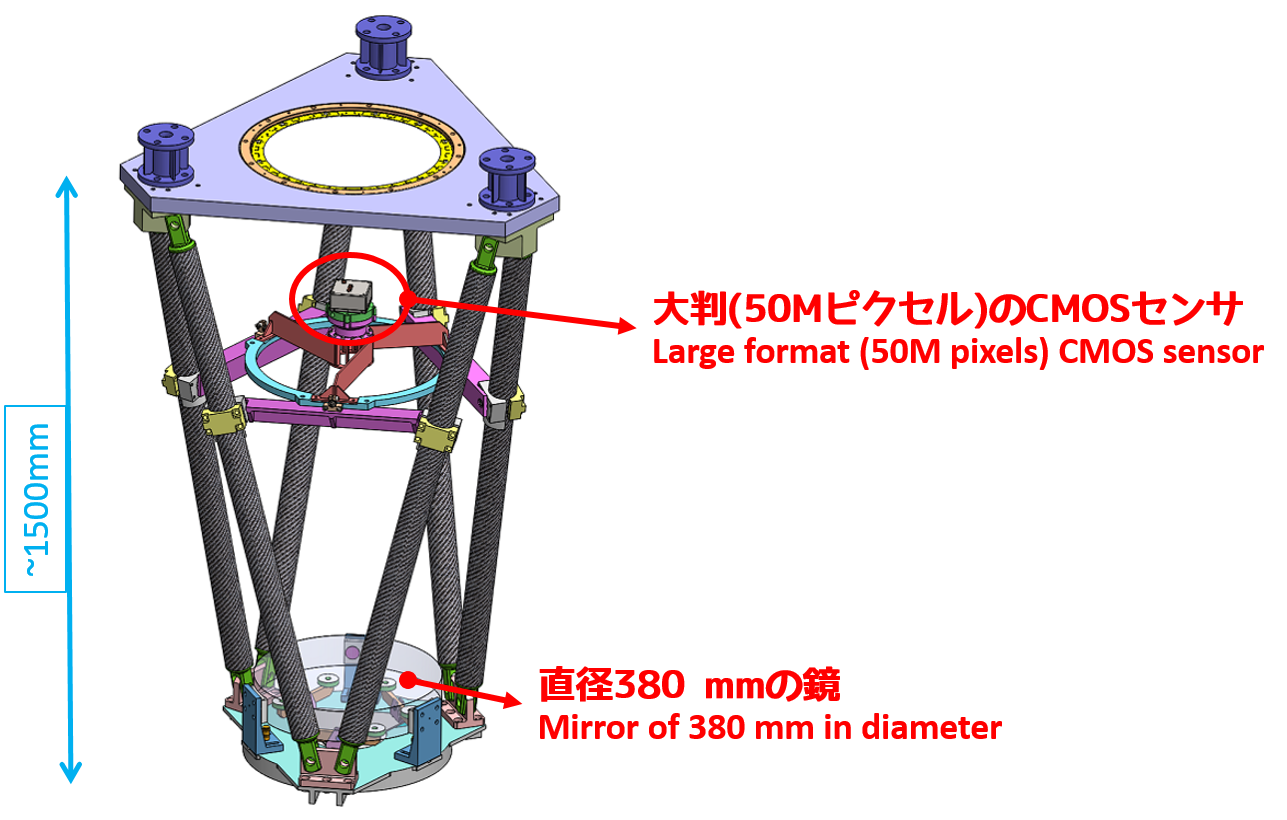
田中賢幸(国立天文台) 筆
PFSで取得するデータは実に膨大なものになります。 現在のサーベイ計画では、2400本のファイバーをフル活用し、一晩で約6万7千本ものスペクトルをとる予定です。 さらに個々のスペクトルからは銀河の赤方偏移や、輝線・吸収線の強度、星のスペクトル型など、実に様々な物理量が測られます。これらはまさに『ビッグデータ』というべき、膨大なデータ量になります。
このようなビッグデータは、科学者が一つ一つのファイルを読んで、解析して、数字を計算して…というような昔ながらのやり方では到底取り扱うことができません。 そこで情報を整理して保存したデータベースを作り、必要なデータを効率よく引き出せるようにする必要があります。 さらにはデータベースから抽出されたデータを解析するツールも必要となります。
PFSはこのデータベースの準備も進めています。 国立天文台とジョンズ・ホプキンス大学が協力して、データベースのプロトタイプシステムのを開発を進めてきました。 国立天文台の持つHSC (Hyper Sprime-Cam)のデータベースを基にした技術と、ジョンズ・ホプキンス大学の推進している SciServer(サイサーバー) の技術を足し合わせることで、画像データも分光データも扱えるようにした、プロトタイプシステムが先日コラボレーションに公開されました。

国立天文台とジョンズ・ホプキンス大学のデータベース開発チーム
これから、サーベイを行うユーザーにプロトタイプシステムを使ってもらい、その使い勝手や必要な機能について意見を募り、実際の運用で使用するデータベースの開発にフィードバックする段階に入ります。今から数年をかけて実際に科学解析に耐えうるシステムを構築していく予定です。

内部公開されたデータベース・プロトタイプシステムのトップページ
{kind=link}